浏览器显示中文字符输出乱码
哈哈哈,其实首页的注释是我特地打上去的
主要是因为有张图一直放在我桌面,想清理桌面又不想把这图就这么删掉,那就稍微记录一下就好


情景分析
前不久接手一个web老项目,里面的代码有的还是1997年的IE4代码,看起来十分的复杂,此外web端输出的也并不是UTF-8编码,而是中国特色国标码GBK,我本地的代码都是用UTF8保存,上传后打开,中文的地方就全变成了古文。
此外打开原有的文件也是方块问号�,就像玩日本游戏输出的那个,有时候也会输出锟斤拷锟斤拷锟斤拷锟斤拷
情景复现
因为网上看到的很多都是用java、python输出的,虽然不复杂,但还是有点麻烦,所以用最老式的方式来复原一下下面这张图
准备工具
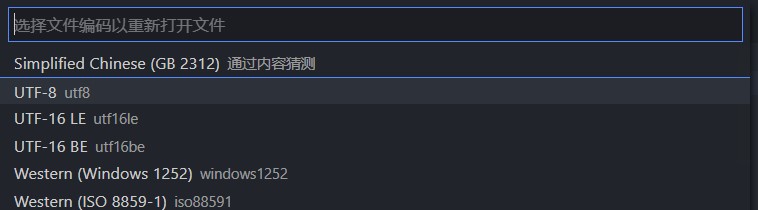
一个可以随时切换编码格式的Visual Studio Code足矣
一句话,我这里是"这是我用来测试的一段文字,谢谢"
开始复现
- 以
UTF8为默认格式,VS Code里面随便输入一段中文,然后点击右下角的编码格式

更换成GBK或GB2312:输出古文码
杩欐槸鎴戠敤鏉ユ祴璇曠殑涓€娈垫枃瀛楋紝璋㈣阿
更换成ISO8859,输出符号码
è¿æ¯æç¨æ¥æµè¯çä¸æ®µæåï¼è°¢è°¢
- 以
GBK或GB2312为默认格式,输入中文再更换编码格式
更换成UTF8,输出口字码
�������������Ե�һ�����֣�лл
更换成ISO8859,输出拼音码
ÕâÊÇÎÒÓÃÀ´²âÊÔµÄÒ»¶ÎÎÄ×Ö£¬Ð»Ð»
- 问句码,我倒是感觉可能是emoji,改成utf8mb4就行,平常能看到四个问号的一般就是emoji
- 至于
锟斤拷,因为感觉编辑器比较智能,没能调的出来,但是具体原理是:
源于GBK字符集和Unicode字符集之间的转换问题。Unicode和老编码体系的转化过程中,肯定有一些字,用Unicode是没法表示的,Unicode官方用了一个占位符来表示这些文字,这就是:U+FFFD REPLACEMENT CHARACTER。那么U+FFFD的UTF-8编码出来,恰好是 \xef\xbf\xbd。如果这个\xef\xbf\xbd,重复多次,例如 \xef\xbf\xbd\xef\xbf\xbd,然后放到GBK/CP936/GB2312/GB18030的环境中显示的话,一个汉字2个字节,最终的结果就是:锟斤拷——锟(0xEFBF),斤(0xBDEF),拷(0xBFBD)。
总结
| 名称 | 示例 | 特点 | 产生原因 |
|---|---|---|---|
| 古文码 | 杩欐槸鎴戠敤鏉ユ祴璇曠殑涓€娈垫枃瀛楋紝璋㈣阿 | 大多为不认识的古文,夹杂日韩文 | 以GBK读取UTF8编码中文 |
| 口字码 | �������������Ե�һ�����֣�лл | 大部分为小方块 | 以UTF8方式读取GBK编码中文 |
| 符号码 | è¿æ¯æç¨æ¥æµè¯çä¸æ®µæåï¼è°¢è°¢ | 大部分为各种符号 | 以ISO8859读取UTF8编码中文 |
| 拼音码 | ÕâÊÇÎÒÓÃÀ´²âÊÔµÄÒ»¶ÎÎÄ×Ö£¬Ð»Ð» | 大部分为头顶有音调符号的字母 | 以ISO8859读取GBK编码中文 |
| 问句码 | 这是我用来测试的一段文字,谢?? 或者是嘻嘻???? | 字符串偶数正常,长度为奇数末尾有问号,或者莫名其妙4个问号 | 以GBK读取UTF8编码中文,再用UTF8格式再次读取。4个问号是因为不支持4个字节表示的emoji |
| 锟拷码 | 锟斤拷锟斤拷锟斤拷锟斤拷锟斤拷锟斤拷 | 全是锟斤拷 | UTF8方式读取GBK编码中文,又用GBK的格式再次读取 |
所以下次再看到乱码,用VS Code自动识别一下编码格式读取即可